Различия в методологиях моделирования машинного обучения
Машинное обучение (ML) - это тип искусственного интеллекта, который упрощенно можно определить как: системы учатся на основе прошлого, чтобы предсказывать будущее [1].
Алгоритмы используются для «изучения» взаимосвязи между переменными данных. Другое определение гласит: «Алгоритм машинного обучения изучает паттерны в многомерном пространстве без какого-либо конкретного направления» [2]. В прогнозной аналитике или прогнозном моделировании эти отношения затем могут быть применены к новому набору данных для прогнозирования результатов. Оно отличается от традиционного статистического моделирования тем, что «правила» заранее не известны. Согласно DataRobot, поставщику автоматизированного машинного обучения для предприятий: «В то время как большая часть статистического анализа основана на принятии решений на основе правил, машинное обучение отлично справляется с задачами, которые трудно определить с помощью точных пошаговых правил»; и «машинное обучение может применяться к многочисленным бизнес-сценариям, в которых результат зависит от сотен факторов, которые трудно или невозможно уследить человеку» [3]. У каждой статистической модели и машинного алгоритма есть свои ограничения, но есть много случаев использования, когда и то, и другое используются для достижения более высокой точности и большей ясности в отношении причинно-следственных связей [4].
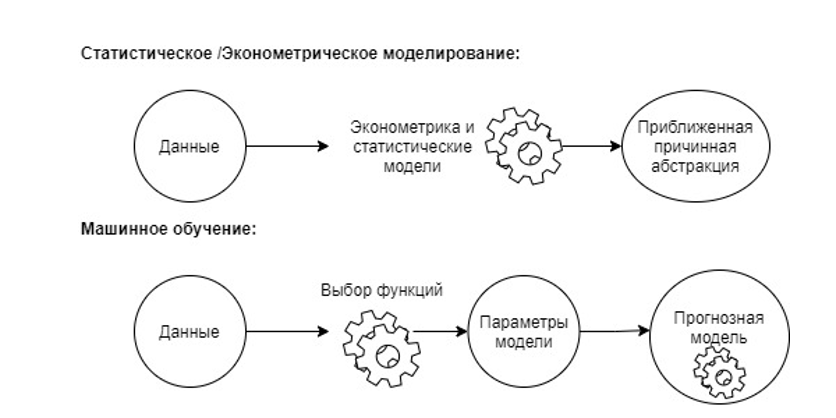
Рисунок ниже иллюстрирует различия в методологиях. Например, традиционная модель оценки может быть реализована путем применения методологии, которая использует уравнение для описания взаимосвязи между стоимостью актива и одной или несколькими переменными. Наблюдая за этими отношениями, можно получить общее представление о влиянии каждой переменной, такой как местоположение, размер объекта и качество здания, на стоимость активов, так как выходом является аппроксимация причинно-следственной связи на основе наблюдаемых взаимосвязей в данных. В автоматизированной модели оценки с машинным обучением ключевые характеристики автоматически определяются на основе статистической значимости по отношению к стоимости, а затем используются для структурирования методологии прогнозирования с использованием прогрессивного набора шагов и оптимизации по точности, сложности и другим факторам. Учитывая набор характеристик актива, модель может выдавать прогнозируемое значение, а в некоторых случаях - коэффициент ошибок для этого прогноза. При обучении модели создается прогнозная модель, которую можно использовать для прогнозирования немаркированных данных. Модель также создается как компромисс между точностью и стабильностью модели.
- DataRobot. AI Experience New York. 2018. URL: https://www.datarobot.com/ai-experience/new-york.
- Prado, M. L. De. (2018). The 10 reasons most machine learning funds fail. Retrieved from https://www.QuantResearch.org
- Machine Learning | DataRobot Artificial Intelligence Wiki. (n.d.). Retrieved June 17, 2018, from https://www.datarobot.com/wiki/machine‐learning/
- Sadler, M. P. (2018). Data Science and Advanced Analytics : An integrated framework for creating value from data.
