Основные критерии подходов к машинному обучению
Существует несколько основных категорий подходов к машинному обучению:
Обучение с учителем: в обучении с учителем алгоритмы описывают взаимосвязь между входными переменными или векторами входных данных и наблюдаемыми результатами и применяют их к новым входным данным для прогнозирования результата. Наблюдаемые и прогнозируемые результаты являются целевой переменной или целевым вектором. Когда обучающие данные включают результаты, их иногда называют «помеченными данными» [1]. Примером результатов может быть процентная ставка по ипотеке с учетом характеристик собственности и характеристик заемщика.
Контролируемые проблемы можно далее разбить на задачи классификации и регрессии:
- Проблемы классификации: это включает разбиение наборов данных на конечное число сегментов или классификаций [1]. Например, можно разделить активы недвижимости на рекомендации для наиболее и наиболее эффективных типов использования на основе известных атрибутов, используя прошлые примеры исследований.
- Проблемы регрессии: регрессия нацелена на получение значения в непрерывном спектре целевой переменной на основе входных данных. Примером может служить прогнозирование стоимости активов недвижимости с учетом набора качеств активов и характеристик рынка.
Обучение без учителя: обучение без учителя отличается от обучения с учителем тем, что для начала не существует наблюдаемых результатов. Вместо этого выходными данными модели являются наблюдения за самими данными, также известные как немаркированные данные. Проблемы неконтролируемого обучения включают оценку плотности (определение концентрации близких или похожих переменных в наборе данных), сбор и использование данных Интернета вещей (IoT) и визуализацию данных.
Обучение без учителя может использоваться как для кластеризации, так и для уменьшения размерности:
- Кластеризация: используется для определения групп схожих точек данных при отсутствии определенных выходных данных [1]. Примером в сфере недвижимости является разделение активов на группы на основе физической близости и характеристик здания.
- Снижение размерности: это часто является компонентом предварительной обработки данных или компонентом других процессов машинного обучения для упрощения или преобразования данных [1]. Это можно использовать в визуализациях данных, таких как сопоставление, и при сжатии данных для больших наборов данных, например, созданных устройствами с поддержкой IoT.
Есть также способы комбинировать контролируемое и неконтролируемое обучение, называемое полу-контролируемым обучением, для достижения лучших результатов, когда только некоторые данные помечены как данные.
Обучение с подкреплением: в задачах обучения с подкреплением нет заданного результата, но компьютер должен достичь оптимального результата методом проб и ошибок [1]. Этот тип обучения обычно ассоциируется с ИИ и, как один из примеров, был использован для создания систем, в которых компьютеры могут играть в игры. В широко разрекламированном примере в 2016 году AlphaGo от Google обыграла лучшего игрока в го в мире, используя свою способность проверять и «запоминать» многие потенциальные результаты миллионов различных комбинаций ходов [2].
В рисунке ниже перечислены некоторые типы доступных методологий машинного обучения, а также типы приложений, в которых они могут быть использованы. Эта диаграмма была адаптирована из шпаргалки по алгоритмам Scikit Learn, шпаргалки по алгоритмам SAS и картам типов алгоритмов машинного обучения Isazi Consulting.
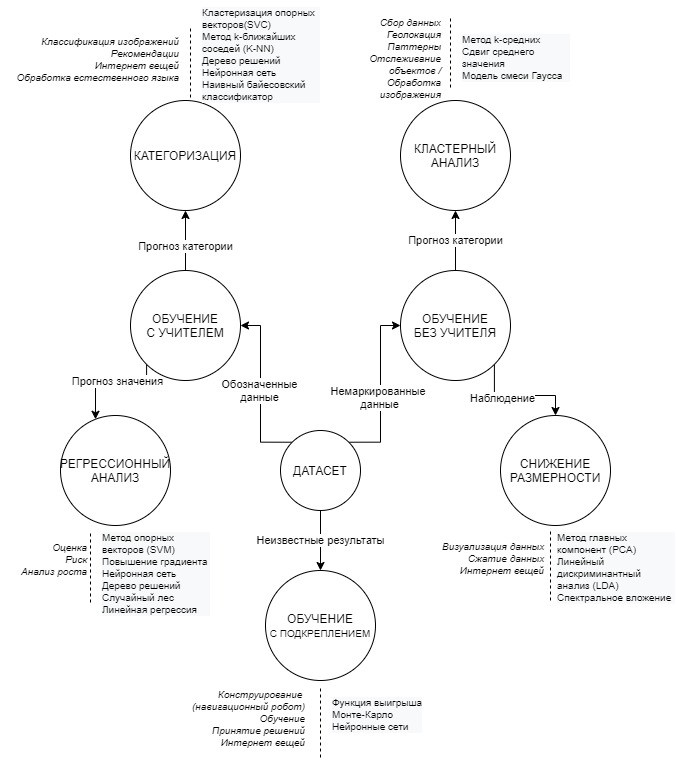
Как показано на этой упрощенной карте машинного обучения, существует множество фреймворков машинного обучения, описанных одним техническим директором как «зоопарк», и может быть трудно понять, что использовать, когда и где [3]. Есть несколько популярных пакетов программного обеспечения для машинного обучения с открытым исходным кодом, в которых можно найти эти фреймворки, включая TensorFlow, Apache Spark, SciKit ‐ Learn и Amazon Machine Learning, которые могут быть полезны специалистам по обработке данных, когда они пытаются найти лучшие методологии. Кроме того, новые сервисы, такие как автоматизированная платформа машинного обучения DataRobot, могут позволить тестировать десятки или сотни различных алгоритмов и комбинаций алгоритмов без наличия у тестировщика опыта в области науки о данных, иначе известный как метод «бросания спагетти в стену».
Как правило, для того, чтобы модель машинного обучения «изучила» взаимосвязи в данных или предсказала результаты, ей предоставляется обучающий набор данных, который является подмножеством всех доступных данных. Остальные данные - это набор для испытаний или набор удерживающих устройств. После того, как модель была обучена с использованием обучающего набора, результаты применяются к удерживающему набору и оцениваются на точность [1].
В случаях, когда наборы данных небольшие и требуется больше данных, можно использовать методы перекрестной проверки. Данные разбиваются на наборы, и модель запускается несколько раз, при этом каждый раз сохраняется другой набор. Затем результаты этих прогонов объединяются в среднее значение, которое лучше всего описывает весь набор. Однако это может быть проблематично, поскольку выполнение нескольких обучающих прогонов требует большей вычислительной мощности, а процесс может привести к большей сложности модели [1].
Прогностические модели имеют дело с неопределенностью и включают теорию вероятностей для прогнозирования, которое может сопровождаться вероятностью точности в определенных приложениях. Затем эти результаты необходимо изучить через призму теории принятия решений, чтобы их в оптимальное решение для данной проблемы [1].
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning. (B. Jordan, Michael; Kleinberg, Jon; Scholkopf, Ed.), Information Science and Statistics. Springer. https://doi.org/10.1117/1.2819119 .
- Moyer, C. (2016). How Google’s AlphaGo Beat Lee Sedol, a Go World Champion. The Atlantic. Retrieved from https://www.theatlantic.com/technology/archive/2016/03/the‐invisible‐opponent/475611/ (дата обращения: 15.10.2020).
- Zhou, Gang & Ji, Yicheng & Chen, Xiding & Zhang, Fangfang. (2018). Artificial Neural Networks and the Mass Appraisal of Real Estate. International Journal of Online Engineering (iJOE). 14. 180.
