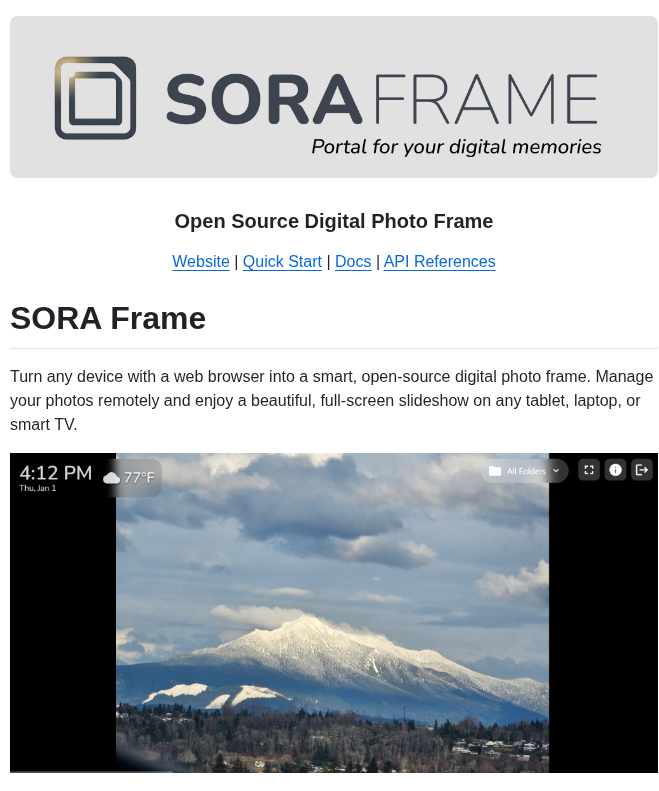
Собираю ссылки на опубликованные файлы из Национальной библиотеки. Раньше выкачивал выдачу через...
Собираю ссылки на опубликованные файлы из Национальной библиотеки. Раньше выкачивал выдачу через API, но часть материалов не скачал
Доработать пайплайн загрузки, конечно, нужно, однако есть альтернативные способы для поиска прямых ссылок на PDF:
— парсинг Google Search
— вебархив (web.archive.org)
— выдача Яндекса
— выдача DuckDuckGo
Какие-то способы может еще есть?
Доработать пайплайн загрузки, конечно, нужно, однако есть альтернативные способы для поиска прямых ссылок на PDF:
— парсинг Google Search
— вебархив (web.archive.org)
— выдача Яндекса
— выдача DuckDuckGo
Какие-то способы может еще есть?