Есть датасет: около 20 тыс. изображений в base64
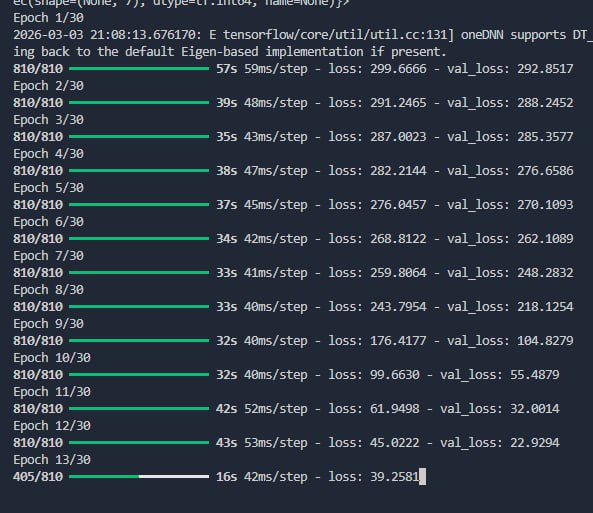
Модель — CNN + BiLSTM + CTC в Keras, вход 200×50×3.Сейчас дообучаю эту версию. Конечно, логичнее было бы перейти на что-то вроде transformer-based подхода (encoder–decoder с cross-attention), дабы быть на стиле с современными моделями для текста в изображениях
Пока оставляю текущий пайплайн -- быстро и предсказуемо. Посмотрим как он поведет себя результат